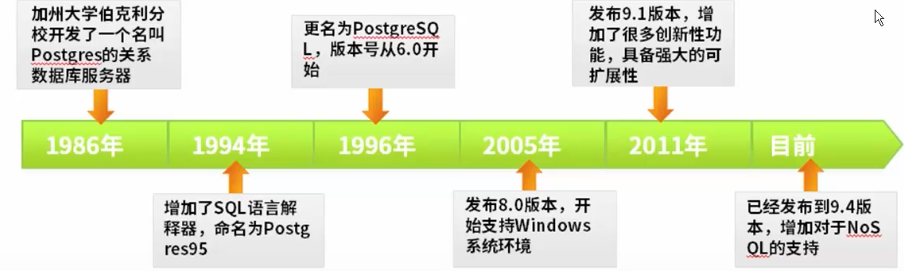
postgreSQL
主要特点:
开源, 免费, 平台可移植性
官方文档: https://www.postgresql.org/docs
基本教程
安装(macOS)
1
2
3
4
5
6
7
8
9
10
# 安装
brew install postgresql@15
# 配置环境变量
echo 'export PATH="/opt/homebrew/opt/postgresql@15/bin:$PATH"' >> ~/.zshrc
# 安装目录
/opt/homebrew/opt/postgresql@15/bin/postgres
# 运行文件目录
/opt/homebrew/var/postgresql@15
# 启动postgres服务
brew services start postgresql@15
验证是否安装成功(创建数据库)
1
createdb mydb
访问数据库
激活数据库
1
psql mydb
1
2
mydb=> 普通用户
mydb=# root用户
查看psql版本版本
1
SELECT version();
该psql程序有许多非 SQL 命令的内部命令。它们以反斜杠字符“ \”开头。例如,您可以通过键入以下内容获取有关各种PostgreSQL SQL命令语法的帮助:
1
mydb=> \h
要退出psql,请输入:
1
mydb=> \q
要查看更多内部命令,请在提示符下输输入
1
mydb=>\?
sql
导入sql: 导入名为basics.sql的sql脚本
1
mydb=# \i basics.sql
创建表
1
2
3
4
5
6
7
CREATE TABLE weather (
city varchar(80),
temp_lo int, -- low temperature
temp_hi int, -- high temperature
prcp real, -- precipitation
date date
);
varchar(80)指定一种数据类型,可以存储长度不超过 80 个字符的任意字符串。
int是普通的整数类型
real是用于存储单精度浮点数的类型。
date 日期
第二张表
1
2
3
4
CREATE TABLE cities (
name varchar(80),
location point
);
The point type is an example of a PostgreSQL-specific data type.
删除表
1
DROP TABLE tablename;
插入
1
INSERT INTO weather VALUES ('San Francisco', 46, 50, 0.25, '1994-11-27');
Constants that are not simple numeric values usually must be surrounded by single quotes (')
1
INSERT INTO cities VALUES ('San Francisco', '(-194.0, 53.0)');
The point type requires a coordinate pair as input.
第二种插入方式(指出列)
1
2
INSERT INTO weather (city, temp_lo, temp_hi, prcp, date)
VALUES ('San Francisco', 43, 57, 0.0, '1994-11-29');
查询表
1
SELECT * FROM weather;
在查询时进行计算 (as可以用来起别名)
1
SELECT city, (temp_hi+temp_lo)/2 AS temp_avg, date FROM weather;
and
1
SELECT * FROM weather WHERE city = 'San Francisco' AND prcp > 0.0;
排序
1
SELECT * FROM weather ORDER BY city;
1
SELECT * FROM weather ORDER BY temp_hi;
去重
1
select distinct city from weather order by city;
join 表之间的连接
所有字段*, 还给可以给表起别名
1
SELECT * FROM weather w JOIN cities c ON w.city = c.name;
特定字段
1
2
SELECT city, temp_lo, temp_hi, prcp, date, location
FROM weather JOIN cities ON city = name;
加上表名.字段(当列名重复的是)
1
2
3
SELECT weather.city, weather.temp_lo, weather.temp_hi,
weather.prcp, weather.date, cities.location
FROM weather JOIN cities ON weather.city = cities.name;
另一种连接方式
1
SELECT * FROM weather, cities WHERE city = name;
上面的连接方式都是内连接
左外连接
因为连接运算符左侧的表的每一行都会在输出中至少出现一次,而右侧的表只会输出与左表中某些行匹配的行。当输出左表中没有与右表匹配的行时,右表的列将替换为空 (null)
1
SELECT * FROM weather LEFT OUTER JOIN cities ON weather.city = cities.name;
自连接
1
2
3
4
SELECT w1.city, w1.temp_lo AS low, w1.temp_hi AS high,
w2.city, w2.temp_lo AS low, w2.temp_hi AS high
FROM weather w1 JOIN weather w2
ON w1.temp_lo < w2.temp_lo AND w1.temp_hi > w2.temp_hi;
聚合函数
An aggregate function computes a single result from multiple input rows. For example, there are aggregates to compute the count, sum, avg (average), max (maximum) and min (minimum) over a set of rows.
1
select max(temp_lo) from weather;
聚合函数不能用在where条件中
This restriction exists because the WHERE clause determines which rows will be included in the aggregate calculation; so obviously it has to be evaluated before aggregate functions are computed.
如果想查询最大天气对应的城市,
1
2
# 这种方式行不通
SELECT city FROM weather WHERE temp_lo = max(temp_lo); WRONG
可以使用子查询(subquery)来完成目标
1
select city from weather where temp_lo = (select max(temp_lo) from weather);
This is OK because the subquery is an independent computation that computes its own aggregate separately from what is happening in the outer query.
聚合函数通常和group by子句联合使用
根据城市分组, 查看城市最大低温,以及城市数量count
1
2
3
SELECT city, count(*), max(temp_lo)
FROM weather
GROUP BY city;
having 对分组结果进行过滤
1
2
3
4
SELECT city, count(*), max(temp_lo)
FROM weather
GROUP BY city
HAVING max(temp_lo) < 40;
模糊匹配, f we only care about cities whose names begin with “S”,
1
2
3
4
SELECT city, count(*), max(temp_lo)
FROM weather
WHERE city LIKE 'S%' -- (1)
GROUP BY city;
where子句和having子句的区别
It is important to understand the interaction between aggregates and SQL’s WHERE and HAVING clauses. The fundamental difference between WHERE and HAVING is this: WHERE selects input rows before groups and aggregates are computed (thus, it controls which rows go into the aggregate computation), whereas HAVING selects group rows after groups and aggregates are computed. Thus, the WHERE clause must not contain aggregate functions; it makes no sense to try to use an aggregate to determine which rows will be inputs to the aggregates. On the other hand, the HAVING clause always contains aggregate functions. (Strictly speaking, you are allowed to write a HAVING clause that doesn’t use aggregates, but it’s seldom useful. The same condition could be used more efficiently at the WHERE stage.)
Another way to select the rows that go into an aggregate computation is to use FILTER, which is a per-aggregate option:
1
2
3
SELECT city, count(*) FILTER (WHERE temp_lo < 45), max(temp_lo)
FROM weather
GROUP BY city;
解释: FILTER只作用在声明了它的查询字段上
FILTER is much like WHERE, except that it removes rows only from the input of the particular aggregate function that it is attached to. Here, the count aggregate counts only rows with temp_lo below 45; but the max aggregate is still applied to all rows, so it still finds the reading of 46.
update(更新)
1
2
3
UPDATE weather
SET temp_hi = temp_hi - 2, temp_lo = temp_lo - 2
WHERE date > '1994-11-28';
返回: UPDATE 2(影响行数)
delete (删除 )
1
DELETE FROM weather WHERE city = 'Hayward';
返回: DELETE 1(影响行数)
不加where条件会清空整张表的数据(危险操作)
高级特性
视图
1
2
3
4
5
6
CREATE VIEW myview AS
SELECT name, temp_lo, temp_hi, prcp, date, location
FROM weather, cities
WHERE city = name;
SELECT * FROM myview;
外键
1
2
3
4
5
6
7
8
9
10
11
12
CREATE TABLE cities (
name varchar(80) primary key,
location point
);
CREATE TABLE weather (
city varchar(80) references cities(name), --外键
temp_lo int,
temp_hi int,
prcp real,
date date
);
1
2
INSERT INTO weather VALUES ('Berkeley', 45, 53, 0.0, '1994-11-28');
插入之前会先校验外键对应表数据是否存在, 如果不存在, 则插入失败, 保证了数据的完整性
1
2
ERROR: insert or update on table "weather" violates foreign key constraint "weather_city_fkey"
DETAIL: Key (city)=(Berkeley) is not present in table "cities".
事务
事务的ACID
案例-转账
1
2
3
4
5
6
7
8
UPDATE accounts SET balance = balance - 100.00
WHERE name = 'Alice';
UPDATE branches SET balance = balance - 100.00
WHERE name = (SELECT branch_name FROM accounts WHERE name = 'Alice');
UPDATE accounts SET balance = balance + 100.00
WHERE name = 'Bob';
UPDATE branches SET balance = balance + 100.00
WHERE name = (SELECT branch_name FROM accounts WHERE name = 'Bob');
使用事务
1
2
3
4
5
BEGIN;
UPDATE accounts SET balance = balance - 100.00
WHERE name = 'Alice';
-- etc etc
COMMIT;
回滚, 保存点
1
2
3
4
5
6
7
8
9
10
11
BEGIN;
UPDATE accounts SET balance = balance - 100.00
WHERE name = 'Alice';
SAVEPOINT my_savepoint;
UPDATE accounts SET balance = balance + 100.00
WHERE name = 'Bob';
-- oops ... forget that and use Wally's account
ROLLBACK TO my_savepoint;
UPDATE accounts SET balance = balance + 100.00
WHERE name = 'Wally';
COMMIT;
如果在交易过程中,我们决定不想提交(也许我们只是注意到 Alice 的余额变为负数),我们可以发出命令ROLLBACK而不是COMMIT,这样我们迄今为止的所有更新都将被取消。
PostgreSQL actually treats every SQL statement as being executed within a transaction. If you do not issue a BEGIN command, then each individual statement has an implicit BEGIN and (if successful) COMMIT wrapped around it. A group of statements surrounded by BEGIN and COMMIT is sometimes called a transaction block.
通过使用保存点,可以更精细地控制事务中的语句。保存点允许您选择性地丢弃事务的某些部分,同时提交其余部分。使用 定义保存点后SAVEPOINT,如果需要,您可以使用 回滚到该保存点ROLLBACK TO。在定义保存点和回滚到该保存点之间,事务的所有数据库更改都将被丢弃,但保存点之前的更改将被保留。
回滚到某个保存点后,该保存点仍然有效,因此您可以多次回滚到该保存点。相反,如果您确定不需要再次回滚到某个保存点,则可以将其释放,以便系统释放一些资源。请记住,释放或回滚到某个保存点都会自动释放在该保存点之后定义的所有保存点。
所有这些都发生在事务块内,因此对其他数据库会话不可见。当您提交事务块时,已提交的操作将作为一个单元对其他会话可见,而回滚的操作则完全不可见。
窗口函数
导入postgresql源码目录中src/tutorial的表
inheritance
Conclusion
进阶教程(开发应用)
Postgresql特点开源, 高度兼容sql标准, 支持ACID
https://github.com/dongxuyang1985/postgresql_dev_guide?tab=readme-ov-file
安装pgAdmin4 可视化连接工具(类似sqlyog, DataGrip)
sql
1
2
3
4
5
6
7
8
9
10
11
12
select first_name, last_name from employees;
-- 别名
select first_name as "名", last_name "姓" from employees;
-- 查询所有字段
select * from employees;
-- 对查询结果去重
select distinct department_id,job_id from employees;
-- 单行注释
/**
多行注释
*/
比较运算符
1
2
3
4
5
6
-- 比较运算符 = != <> > >= < <=
select * from employees where employee_id = 100;
select * from employees where employee_id != 100;
select * from employees where salary > 10000;
-- 闭区间查询, 包括区间端点
select * from employees where salary between 9000 and 12000;
模糊查询
1
2
3
4
5
6
7
8
9
10
11
12
13
14
-- 查询以S开头的first_name, %匹配多个
select first_name from employees where first_name like 'S%';
-- 查询以s结尾的first_name, %匹配多个
select first_name from employees where first_name like '%s';
-- 包含s的first_name
select first_name from employees where first_name like '%s%';
-- 模糊匹配一个字符_, 查询首字母任意,后面字符为uis
select first_name from employees where first_name like '_uis';
-- 转义字符, 如果要匹配结果中有%或_就需要转义, 默认使用反斜杠\为转义符号标识
select first_name from employees where first_name like '%25\%%';
-- 匹配不区分大小写
select first_name from employees where first_name ILIKE '%s%';
-- 反向匹配
select first_name from employees where first_name not ILIKE '%s%';
空值判断
1
2
3
4
5
6
7
8
9
-- 为空
select * from employees where manager_id isnull;
-- 非空
select * from employees where manager_id notnull;
-- is distinct from null 是等值判断, 但是支持空值判断, 1 = null, 1 !=null这些没有用的
-- 1是否和null不同
select 1 is distinct from null;
select 1 is not distinct from null;
and, or
1
2
3
4
5
6
7
8
9
10
11
12
-- 复杂查询条件
select * from employees where first_name = 'Steven' and last_name = 'King';
select * from employees where first_name = 'Steven' or last_name = 'King';
-- 在pg中, and or使用的是短路运算, 只要前面的表达式满足整体表达式的结果, 后面的表达式就不再进行计算了
select 1=1 or 1/0=1; -- 不会报错, 因为后面的短路了
select * from employees where (salary = 10000 or salary = 12000) and department_id = 80;
-- not: not between not in,
select * from employees where not first_name = 'Steven';
-- 优先级 not > and > or
-- 练习
select * from employees where hire_date > '2008-01-01' and salary < 5000 and commission_pct is null;
排序
1
2
3
4
5
6
7
8
9
10
11
12
-- 字符串默认按照字典顺序排列
select employee_id,first_name,last_name,hire_date,salary from employees order by first_name;
-- 日期默认按照从早到晚排
select employee_id,first_name,last_name,hire_date,salary from employees order by hire_date;
-- 降序 desc
select employee_id,first_name,last_name,hire_date,salary from employees order by salary desc;
-- 如果排序的两个字段一样(first_name), 那么按下一个字段排序(last_name)
select employee_id,first_name,last_name,hire_date,salary from employees order by first_name, last_name;
-- null值排序的时候当做一个最大的值(降序,在最后面, 升序在最前面)
select employee_id,manager_id,first_name,last_name,hire_date,salary from employees order by manager_id;
-- 强制指定让null排在最前面, nulls first 或者nulls last
select employee_id,manager_id,first_name,last_name,hire_date,salary from employees order by manager_id nulls first;
分页
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
--获取前10条记录
-- 方式一
select first_name,last_name,salary from employees order by salary fetch first 10 rows only;
-- 方式二
select first_name,last_name,salary from employees order by salary limit 10;
-- with ties 额外返回数据相同的值(salary) limit达不到这种效果
select first_name,last_name,salary from employees order by salary fetch first 10 rows with ties;
-- 分页查询 limit/fetch pageSize offset pageSize*(pageNum-1)
-- 方式1
select first_name,last_name,salary from employees order by salary fetch first 10 rows only offset 0;
--方式2
select first_name,last_name,salary from employees order by salary limit 10 offset 10;
-- 练习:查找月薪第二高的所有员工
select first_name, last_name, salary
from employees
where salary != (select max(salary) from employees)
order by salary desc
fetch first 1 rows with ties;
数据汇总/聚合函数
1
2
3
4
5
6
7
8
-- 数据汇总: 统计条目数, 总和, 平均数, 最大值, 最小值, 只对数值有效
select count(*),sum(salary),avg(salary),max(salary),min(salary) from employees;
-- 聚合函数忽略null的字段
select count(*),count(manager_id) from employees;
-- 统计时去重, 不含null值
select count(distinct manager_id) from employees;
-- string 聚合, "a" + "b" -> "a$$b", 相当于java中reduce函数
select string_agg(first_name, '$$') from employees;
分组 group by 子句
1
2
3
4
5
6
7
8
9
10
11
-- 分组
select hire_date, count(*) from employees group by hire_date;
select extract(year from hire_date), department_id, count(*) from employees group by hire_date,department_id;
-- 空值会被分为一个组
select commission_pct, count(*) from employees group by commission_pct;
-- 分组查询结果的字段, 必须在group by子句中, 否则会报错
-- having子句对分组结果进行过滤
select department_id, count(*) from employees group by department_id having count(*) > 10;
-- 练习,查询哪些部门月薪大于10000的员工人数超过两个
select department_id,salary,count(*) count from employees group by department_id, salary having count(*) >= 2 and salary >= 10000;
高级分组
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
-- 高级分组准备表
create table sales (
item varchar(10),
year varchar(4),
quantity int
);
-- 高级分组准备表数据
insert into sales values ('apple','2018',800);
insert into sales values ('apple','2018',1000);
insert into sales values ('banana','2018',500);
insert into sales values ('banana','2018',600);
insert into sales values ('apple','2019',1200);
insert into sales values ('banana','2019',1800);
-- 高级分组
select * from sales;
-- 统计销量
select sum(quantity) from sales;
-- 统计不同产品的销量
select item, sum(quantity) from sales group by item;
-- 统计不同产品的不同年份的销量
select item, year, sum(quantity) from sales group by item,year;
-- rollup更简单的写法, 可以一次性获取上面所有结果
select item,year,sum(quantity) from sales group by rollup (item, year);
-- coalesce给null值的字段设置一个默认值(相当于mysql的ifnull)
select coalesce(item,'所有产品') as 产品,coalesce(year,'所有年份') as 年份 ,sum(quantity) from sales group by rollup (item, year);
-- cube更多种字段的组合
select coalesce(item,'所有产品') as 产品,coalesce(year,'所有年份') as 年份 ,sum(quantity) from sales group by cube (item, year);
-- 更加通用的grouping sets(rollup和cube是sets的特例)
select coalesce(item, '所有产品') as 产品, coalesce(year, '所有年份') as 年份, sum(quantity)
from sales
group by grouping sets ((item,year),(item),()); --和rollup等价
-- 和cube等价
select coalesce(item, '所有产品') as 产品, coalesce(year, '所有年份') as 年份, sum(quantity)
from sales
group by grouping sets ((item,year),(item),(year),()); --和cube等价
-- grouping 函数, 可以查看结果集是不是聚合结果, 1是聚合结果, 0不是聚合结果
select item,year,sum(quantity),grouping(item), grouping(year) from sales group by rollup (item, year);
连接查询
内连接, 查询两张表中都有的数据
左外连接, 内连接+ 如果左边有, 右边没有也显示
右外连接: 类似左连接
全连接: 左连接 + 右连接
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
-- 连接查询
select * from employees;
select * from departments;
-- 内连接
select d.department_id, e.first_name, d.department_name
from employees e
join departments d
on e.department_id = d.department_id;
-- 外连接
select d.department_id, e.first_name, d.department_name
from employees e
left join departments d
on e.department_id = d.department_id
-- pg中and是连接条件, 不会影响结果行数, 会有很多null值, 所以过滤条件一定要写在where后面
-- and d.department_name = 'IT'
-- where是过滤条件, 对连接的结果进行过滤, 会影响结果行数
where department_name = 'IT';
交叉连接/笛卡尔积(from a,b 或 cross join 或者没有指定任何连接条件时)
using
自连接
多表连接
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
-- 交叉连接(笛卡尔积) 生成一个1-9 * 1-9的乘法表
select concat(t1,'*',t2,'=',t1* t2) from generate_series(1,9) t1
cross join generate_series(1,9) t2;
select *
from employees e
join departments d
-- on d.department_id = e.department_id
-- 两个表的连接字段名相同, 可以使用using关键字简化连接条件
using (department_id);
-- 还能使用自然连接简化: 如果两个表有相同的字段(不推荐, 还是指出连接条件好)
select * from employees e natural join departments d;
-- 自连接, 自己连接自己
select *
from employees e
left join employees m
on e.manager_id = m.employee_id;
-- 多个表的连接
select e.first_name, d.department_name, j.job_title
from employees e
join departments d
on e.department_id = d.department_id
join jobs j
on e.job_id = j.job_id
条件表达式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
-- 条件表达式
select first_name,last_name,
case department_id
when 90 then '管理'
when 60 then '开发'
else '其他'
end as 部门
from employees;
-- 不同部门id的人数
select count(case department_id when 10 then 1 end) dept10_count,
count(case department_id when 20 then 1 end) dept20_count,
count(case department_id when 30 then 1 end) dept30_count
from employees;
-- 过滤count(*)
select count(*) filter (where department_id = 10) dept10_count from employees;
-- 用case来针对范围来返回不同的结果
select first_name, last_name,
case
when salary < 5000 then '低收入'
when salary between 5000 and 10000 then '中等收入'
else '高收入'
end as 收入
from employees;
-- 两个函数: NULLIF coalesce
-- The NULLIF function returns a null value if value1 equals value2; otherwise it returns value1.
select nullif(2,2);
-- 避免除以0错误
select 1/nullif(1,0);
-- Returns the first of its arguments that is not null. Null is returned only if all arguments are null.
-- It is often used to substitute a default value for null values when data is retrieved for display.
select coalesce(1,2,3);
-- 为null设置默认值
select first_name, coalesce(commission_pct,0) from employees;
常用函数
高级教程(运维)
mysql和postgresql的对比

在centos上安装postgresql
https://www.postgresql.org/download/linux/redhat/
1
2
3
4
5
6
7
8
9
10
11
# Install the repository RPM:
sudo yum install -y https://download.postgresql.org/pub/repos/yum/reporpms/EL-7-x86_64/pgdg-redhat-repo-latest.noarch.rpm
# Install PostgreSQL:
sudo yum install -y postgresql15-server
# 安装contrib包,contrib包中包含了⼀些插件和⼯具
sudo yum install postgresql15-contrib
# Optionally initialize the database and enable automatic start:
sudo /usr/pgsql-15/bin/postgresql-15-setup initdb
sudo systemctl enable postgresql-15
sudo systemctl start postgresql-15
centos 7通过yum只能安装15版本的, 要安装最新版本可以使用源码安装
1
2
3
4
5
6
#查看状态:
systemctl status postgresql-15
#停⽌数据库:
systemctl stop postgresql-15
#数据⽬录:
/var/lib/pgsql/15/data
登录数据库
1
2
3
4
su - postgres
psql
# 查看版本,
show server_version;
psql客户端
psql是PostgreSQL中的⼀个命令⾏交互式客户端⼯具,类似于mysql中的 mysql client 以及oralce 中的 sqlplus
“\h”命令
使⽤psql⼯具需要记住的第⼀个命令是“\h”,该命令⽤于查询SQL语句的语法,使⽤“\h”命令可以查看各种SQL 语句的语法,⾮常⽅便 ⽐如忘记如何创建user
1
\h create user
“\d”命令
该命令将显示每个匹配“pattern”(表、视图、索引、序列)的信息,包括对象中所有的列、各列的数据类型、 表空间(如果不是默认的)和所有特殊属性(诸如“OT NULL”或默认值等)等
案例 “\d”命令后什么都不带,将列出当前数据库中的所有表
“\d”命令后⾯跟⼀个表名,表示显示这个表的结构定义
“\d”命令也可以⽤于显示索引信息
“\d”命令后⾯的表名或索引名中也可以使⽤通配符 如“*”或“?”等
使⽤“\d+”命令可以显示⽐“\d”命令的执⾏结果更详细的信息,除了前⾯介绍的信息,还会显示所有与表的 列关联的注释,以及表中出现的OID
匹配不同对象类型的“\d”命令如下
1
2
3
4
5
·如果只想显示匹配的表,可以使⽤“\dt”命令。
·如果只想显示索引,可以使⽤“\di”命令。
·如果只想显示序列,可以使⽤“\ds”命令。
·如果只想显示视图,可以使⽤“\dv”命令。
·如果想显示函数,可以使⽤“\df”命令。
\timing 显示执⾏SQL语句的时间
要想列出数据库中的所有⻆⾊或⽤户,可以使⽤“\du”或“\dg”命令
指定客户端字符集的命令
1
使⽤“\encoding utf8;”命令设置客户端的字符编码为“utf8”